Nominate Now | Top 30 Healthcare Innovators 2026 List Honoring the Executives Driving Measurable Transformation and Responsible Innovation Across the Healthcare Ecosystem.
CDO Magazine Unveils the 40 Most Influential Data Leaders in Finance — North America 2026 Few industries are advancing data and AI as rapidly as financial services. From real-time payments and fraud detection to risk modeling, regulatory compliance, and AI-driven customer experiences, fina...
Webinar | Qlik How AI Is Forcing a Redesign of the Data Organization Date: March 26 Industry experts explore the emergence of new human–AI roles—from AI supervisors and agent coordinators to hybrid data leaders who combine domain expertise with AI fluency
Opinion & Analysis
Data Governance in Data-Driven Organizations
Written by: Julia Bardmesser | CEO of Data4Real, LLC
Updated 11:00 AM UTC, July 10, 2023

In our previous two articles in this series, we discussed the emerging transformation that innovative businesses are undertaking right now. They are evolving from data-enabled to data-driven. We described what this means (hint: it’s more than just hiring more data scientists), as well as the business case and drivers for taking the journey. We further discussed new technologies and architecture patterns that enable the data-driven model.
However, becoming a data-driven business involves more than just introducing new data policies or technology. Putting data into the center of the business requires rethinking some basic ideas. Who owns data if it’s meant to be shared by everyone? Who is responsible for cleaning it? How will you keep data safe and secure? Data-driven organizations optimize the processes, roles, accountabilities and responsibilities for how data is created, stored, protected, shared and maintained. It becomes both safer and easier to share data across the company, as well as with partners, suppliers and customers.
In this article, we:
- Provide an overview and definition of what we mean by data governance.
- Describe how today’s mature, data-enabled organizations typically govern data.
- Discuss the shortcomings of current approaches.
- Describe how data governance evolves in a data-driven model.
Section 1. Defining Data Governance
Since this is an article about data governance written by a data professional, let’s start with a definition. What exactly is data governance?
Definition:
Data governance is a business discipline whose goal is to ensure that data across the enterprise is usable for any business purpose, current or future.
Data Management
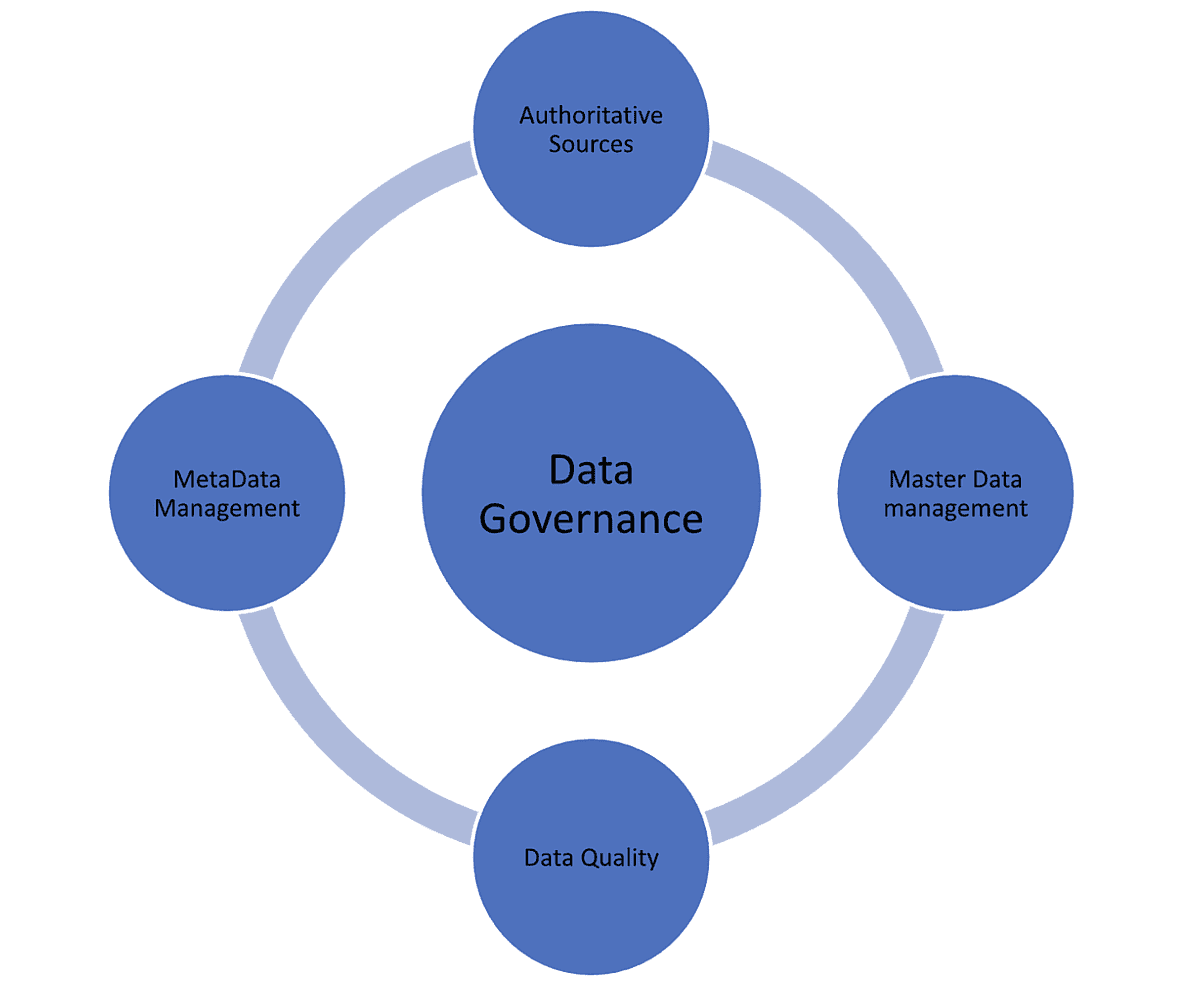
Data Governance.png
Figure 1. The components of a holistic data governance model.
Data management encompasses the technology platforms, operations processes and business stewardship of the key data disciplines depicted in the illustration above.
Data governance is embedded at the center of the data management discipline. It provides the oversight to ensure implementation and measurable success of data management practices. Data governance’s role is to orchestrate the pieces within the data management ecosystem. It provides policies, standards and business processes that tie together data management technology and operations with the business processes required to enable data to become useful.
In our first article, we identified the four stages of data maturity in organizations, from data-aware to data-driven. We summarize the stages below again in Figure 2.
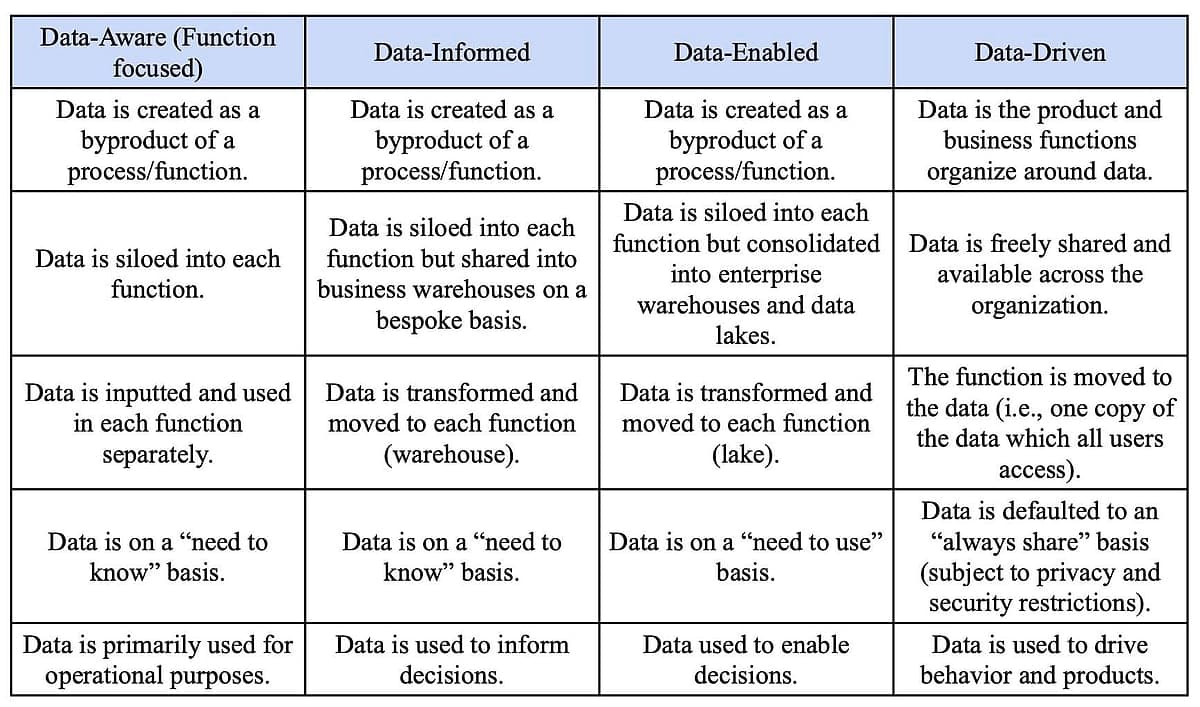
Data Governance.jpg
Figure 2. The four stages of maturity and readiness inside organizations.
As you can imagine, data governance did not exist as a discipline in “data-aware” enterprises. It first appeared as organizations started to progress toward the “data-informed” stage and mostly concentrated on data privacy and access. However, as organizations have moved into a “data-enabled” stage, they have acknowledged that when data is created as a byproduct of a business process, there needs to be a discipline that makes the data usable for other purposes, especially the ones that require cross-silo data. To accomplish that, data governance creates rules and processes to:
- Know and codify which business processes produce data that can appropriately be used by other businesses and functions — authoritative sources governance.
- Recognize the most important business data concepts (e.g., customer, product, account) and steward rules for unique identification and disambiguation of these entities — master data management.
- Understand which level of data quality is fit for different purposes within the enterprise. Create processes to measure and remediate the data that doesn’t meet its assigned quality level — data quality management.
- Understand and make available business and technical descriptions of data elements, including ESG, privacy, retention and information security classifications; collect and make available data lineage — metadata management.
Section 2. Data Governance in Data-Enabled Enterprises
In most data-enabled organizations today, data is governed via a delicate interplay between three types of actors in a company:
- Producers: Typically, this is the business function and function-aligned information technology (IT) team responsible for developing applications that enable a function to operate and create data. This can also include the team(s) making copies of data available for consumption outside of the core business application — for example, loading data into function-aligned operational data stores, data marts, data warehouses or data lakes. Examples of producers, in, say, banks, would be credit card, mortgage loans, corporate loans and securities trading businesses.
- Consumers: These are usually the business end users and the function-aligned IT team that uses someone else’s data for decision support, or who integrate someone else’s data into their own software (which in turn, creates new data, i.e., most of the consumers of data are also producers of derived data). Examples of the consumer functions in banks are corporate finance, credit risk and anti-money laundering compliance functions. As companies move to embrace data and analytics-driven growth, data science/data analytics teams become important consumers of data, though they are still oft-forgotten in data governance structures.
- Governors: These are generally the individuals responsible for ensuring that data is well-managed from cradle to grave. These can include a Chief Data Officer (CDO), a data governance council or committee comprised of producers and consumers that make or regulate policy, a data governance team that supports policy definition, data stewards representing the business functions who enforce policy, and data quality analysts who work with the governance team and data stewards to fix errors.
This organizational model, while much more effective than the access-focused governance of yesterday’s data-informed organizations, is still subject to significant friction between the main actors. There are two main sources of friction. One is the misalignment of priorities between consumers and producers of data. The other is the lack of real enforcement power in the data governance team.
In the data-enabled, application-centric model:
- Producers create and shape data as needed to support the primary operation of the business. They are measured and compensated by how much they can improve the productivity, revenue or net income of their business function. Business executives, product managers and supporting technology teams are not incentivized to make use of any data generated outside of the immediate concerns of the producer business. There is a high-level acknowledgement of the importance of data for either regulatory or overall growth objectives. A lack of data literacy on the part of data producers, however, prevents full engagement. Producers’ short-term needs are prioritized over the long-term needs of the enterprise.
- Governors, on the other hand, are accountable for how effectively data is leveraged in an organization — how good it is, how available it is, and how well-protected it is. Their success is measured by their ability to effectively leverage data. Governors define the policies to make data useful, but are dependent on producers and their willingness to engage (and often fund) data management efforts. Producers are also the ones who are actually responsible for implementing policies, standards and controls.
- Consumers are typically held captive to the needs of the producers. Perhaps the producers’ business will actually fix and define data and make it available to them, perhaps not. It depends on whether producers have the budget, time, resources and a compelling financial interest or imperative to prioritize making data better and available for others’ benefit.
Let’s take a look in detail how these three groups interact across all four areas of data governance:
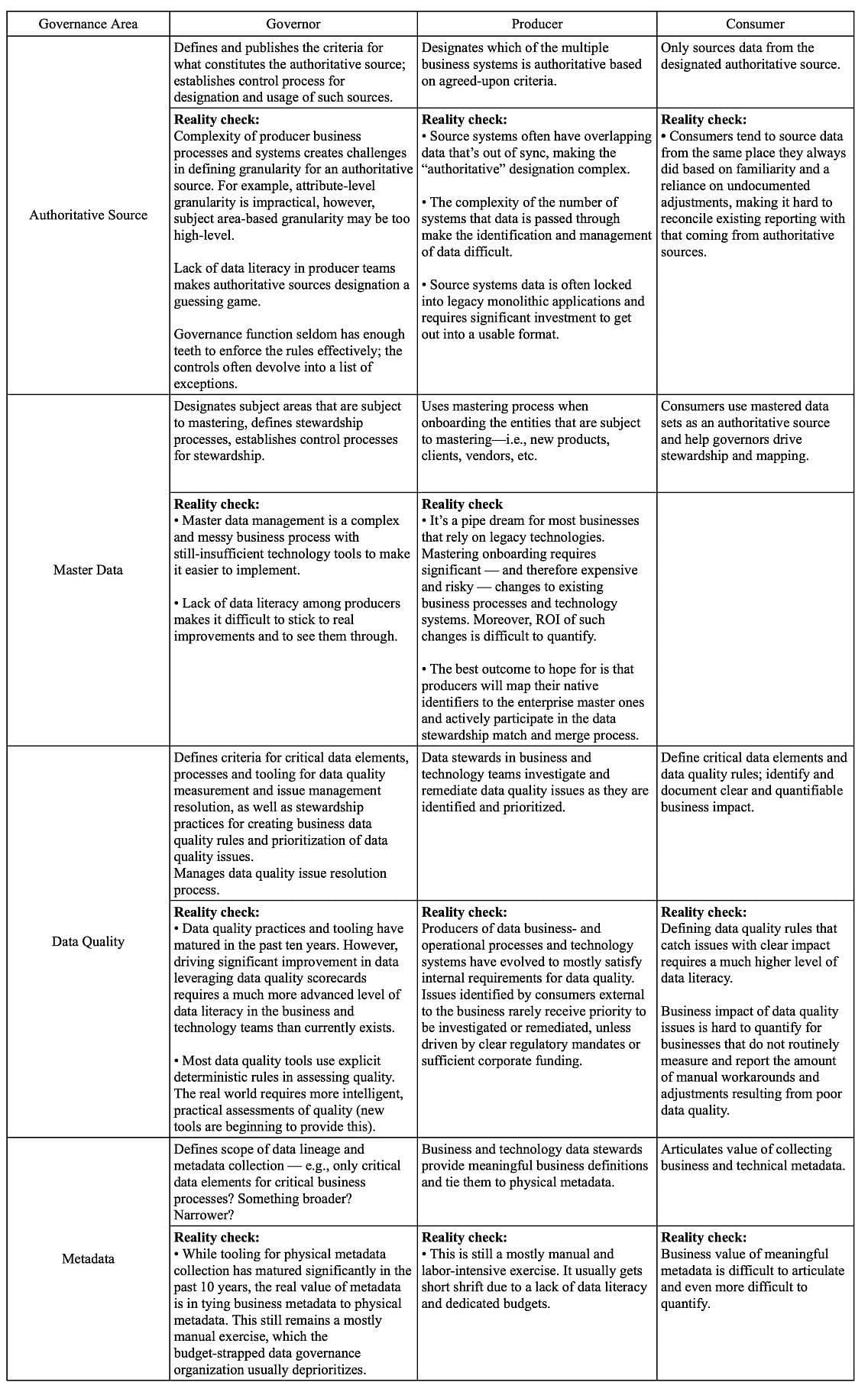
4_20 – Google Sheets.jpg
Section 3. How is Data Governance Different in Data-Driven Enterprises?
Let’s review the definition of the data-driven organization from the first article in our series, then extrapolate how data centricity would inform changes in data governance, structure and practices.
In a data-driven organization, data:
- Becomes the product. Business functions organize around data.
- Is freely shared and available.
- Defaults to “always share.”
- Is used to drive products and behavior.
The adoption of data-centric architectures and new collaborative database technology, which we covered in our second article, enables a successful transformation to a data-driven model. The collaborative database is a common platform where (1) producers can save data for their own operational use; (2) consumers can find and use data for their own operational or analytic needs; and (3) governance can apply common enterprise standards and controls.
There are two major implications for data governance:
- Data doesn’t move. Data is created, stored and used in the same place. Many of the challenges that data governance addresses originate from the movement of data between business applications. In a data-driven architecture, however, data doesn’t move. Any consumer or producer with access to data can immediately observe any transformation. Data provenance, data lineage and data traceability thus become non-issues. Given how much time and money institutions (especially financial institutions with large regulatory mandates) spend on discovering, documenting, visualizing and updating data lineage, this is a huge benefit of the data-driven architecture in and of itself.
- Incentives align. Becoming a data-driven enterprise requires significant changes to internal culture and the social contracts between business functions that produce and consume data. This leads to new incentives for business and technology teams that produce data, in turn improving data literacy (though it might be argued that it’s the other way around — changes in data literacy lead the way for the enterprises to become data-driven). In fact, a misalignment of incentives is a major source behind the previously described “reality checks.”
When data becomes the company’s main asset and product, data quality becomes a priority. The goal of ensuring quality changes how businesses prioritize and fund data, as well as build business and technology architectures. Data governance evolves from a separate, often audit-enforced process into a pervasive business and technology practice. Some current, common data governance practices become obsolete.
Let’s see how this shift in understanding, incentives and technology changes the data governance discipline:
• Producers and consumers utilize data from the same repository as everyone else. They are measured and compensated by the quality and usability of data, which is now one of the enterprise’s main products. Business executives, product managers and supporting technology teams are incentivized to make data useful and usable in ways beyond the immediate application of the producer business. Additionally, for the enterprise that has fully implemented the collaborative database architecture, data quality, data integrity, and data centricity are encoded via self-harmonization properties that autonomously discover and remediate data discrepancies.
In a data-driven organization, the clear line of demarcation between producers and consumers blurs. All functions produce and consume each other’s data, governed by policies around who is allowed to see and change what. Smart contracts, directly embedded in the data itself, enforce policies to prevent one function from accidentally viewing or overwriting data that is critical to another function. Furthermore, all data changes and lineages are natively preserved in collaborative database. If you need to understand the provenance of where data came from, or revert to an earlier snapshot, this can be more easily accomplished.
• Governors are still accountable for and measured by how effectively data is leveraged in an organization — how good, available, and well-protected it is. They will continue to coordinate and work with producers and consumers to ensure that data is always available and of high quality. However, in a data-driven organization, they also play a more active and hands-on role for some data management functions, especially around the creation and enforcement of data access and retention policies. In essence, one of the major implications of data-driven transformation is the direct responsibility of the governors over some governance functions that used to live exclusively within the domain of the producers.
Let’s give an example. Let’s assume that a country has just issued a new data privacy directive. No personally identifiable information about citizens can be exposed to any personnel outside of the country without legal and regulatory approval. A company’s Regulatory Compliance & Legal team has raised the issue, and the governors within the company (the data governance council) modify the company’s data privacy policy. The governors also issue an internal notification socializing the change to the policy, and set an enforcement date. They are accountable for ensuring that the company is compliant with the policy by the enforcement date.
How would this policy be implemented and enforced in a traditional, data-enabled organization? Usually, the task would fall on the producers to execute the change to make the policy real. First, the business leaders in the organization need to know which producers will be impacted by the policy change. Then, the producers will need to request the funding to make changes to their software in how they store or provide access to data about customers in the affected country, so that they can provide the necessary protective controls. They will need to prioritize the effort to implement the change on top of other business priorities. Finally, if originating sources of data about individuals in that country were copied to other operational or analytic data stores, the owners of those systems would also need to invest in changing the access controls in their respective systems to be compliant with the new policy. Those changes will go through the typical software development lifecycle, meaning that producers will modify, test and release code to production systems in line with their respective application lifecycle management processes. Consumers may scan some of their systems or reports to ensure that they flush any affected data based on the policy, but they generally depend on the producers to comply with the policy. Depending on the size and complexity of the organization (and how much personally identifiable information about affected citizens has diffused through the organization), it may take years for the company to be fully compliant.
Let’s contrast this with a data-driven organization that has adopted a data-centric architecture (with a collaborative database). Based on the principles of “defensible data,” governors can directly create a data access policy that limits access and embed it into blocks of data that contain personally identifiable information about individuals from the affected country. Producers and consumers can continue to use the collaborative database, and their applications will be restricted from accessing the data blocks if they do not meet the policy requirements. Governors not only set the enforcement date of the policy—they can directly set the enforcement of the policy itself!
With this example in mind, let’s now take a detailed look at how these three groups interact across all four areas of data governance:
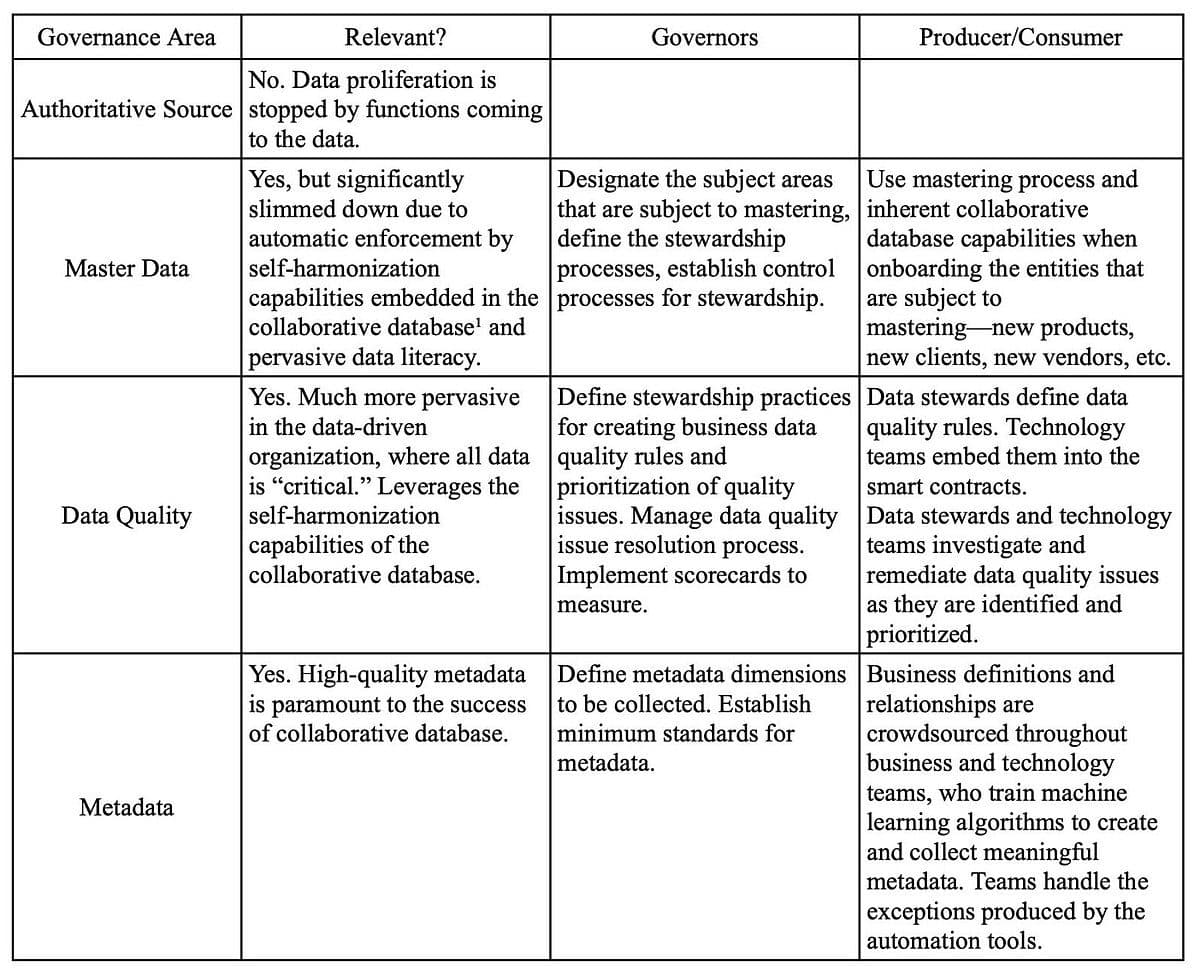
4_20.1 – Google Sheets.jpg
Summary
In new data-centric models, data is treated as the main asset of the enterprise and the driver for its growth and sustainable development. With that shift in focus, incentives and corresponding shift in culture, the data governance/data management function evolves from being overseer and an enforcer of (often) unpopular rules into a business function directly accountable for the success of the various business lines. The concept of producers and consumers is blended into a model where business functions participate in a community. Everyone equally creates and consumes data in a virtuous loop. Each business function may still “own” its composable blocks of data. Data governance, however, oversees the policies that bind composable blocks and organize them into a cohesive chain where data can be discovered and consumed by other parties within and across functions.
Over the course of this series, we (1) described the business value for the transformation to a data-driven culture and model, (2) described the underlying technology architecture and innovations that make this possible, and (3) have described the governance and management implications of managing data in a data-centric way.
So where do you begin? How do you finance a data-driven business transformation initiative? What skills and readiness must exist within your organization? How do you introduce new technologies in a world where you may already have hundreds of databases, mainframes, warehouses or spreadsheets housing data today?
These subjects will be covered in the fourth and final article in this series.
1Much of the potential for disruptive transformation in data governance is dependent on the efficiency and effectiveness of machine learning and AI-based learning systems that make self-harmonization possible. Without machine assistance, the implications for governors, producers and consumers are the same, but more manual efforts would be required.
About the Author
Julia Bardmesser, in her most recent role, was Voya Financial’s Senior Vice President and Head of Data, Architecture, and CRM. She is a board advisor for technology startups The Medici Project and Polymer, and a Women Leaders in Data and AI (WLDA) founding member. Before joining Voya, Bardmesser was Global Head of Data Integration at Deutsche Bank.
With over 20 years of experience in cross-platform solution delivery in the financial industry, architecture, data management, and data governance, she is a much sought-after speaker and mentor. Bardmesser received the 2022 WLDA Changemaker in AI award; was named to CDO Magazine’s List of Global Data Power Women three years in a row (2020-2022); named one of the Top 150 Business Transformation Leaders by Constellation Research in 2019; and was recognized as the Best Data Management Practitioner by A-Team Data Management Insight in 2017. She holds a Master of Arts in Economics from New York University.


