Nominate Now | Top 30 Healthcare Innovators 2026 List Honoring the Executives Driving Measurable Transformation and Responsible Innovation Across the Healthcare Ecosystem.
CDO Magazine Unveils the 40 Most Influential Data Leaders in Finance — North America 2026 Few industries are advancing data and AI as rapidly as financial services. From real-time payments and fraud detection to risk modeling, regulatory compliance, and AI-driven customer experiences, fina...
Webinar | Qlik How AI Is Forcing a Redesign of the Data Organization Date: March 26 Industry experts explore the emergence of new human–AI roles—from AI supervisors and agent coordinators to hybrid data leaders who combine domain expertise with AI fluency
Opinion & Analysis
Exploring Cloud-Native Acceleration of Data Governance
Written by: Willem Koenders | Global Data Strategy Leader, ZS Associates
Updated 3:36 PM UTC, October 6, 2023

The advent of cloud-based technology brings promises of scalability, elasticity, lower costs, rapid deployments, and enhanced compatibility of data technologies. We should add to this list the ability to anchor data governance into the organization “by design” by observing a few data-design principles.
But first: So what?
Any seasoned data governance practitioner knows that implementing data management is only for those with extraordinary perseverance. Identifying and documenting data applications and flows, measuring and remediating data quality, and managing metadata — despite a flood of tools that attempt to automate many data management activities, these typically remain manual and time-consuming.
They are also expensive.
At leading organizations, data governance and remediation programs can top $10 million per year; in some cases, even $100 million. Data governance can be seen as a cost to the organization and a blocker for business leaders with a transformation mandate.
So, here appears our “so-what.” If data governance could be incorporated directly into the fibers of the data infrastructure while the architectural blocks are being built and connected, it would dramatically reduce the need for costly data governance programs later. We will review three essential design features that, once incorporated, ensure that data governance is embedded “by design” rather than by brute manual force.
Adhering to these design features does not imply that design or implementation costs would be higher except for some upfront time to define the data principles and standards and some SME time during the program to ensure their understanding and incorporation.
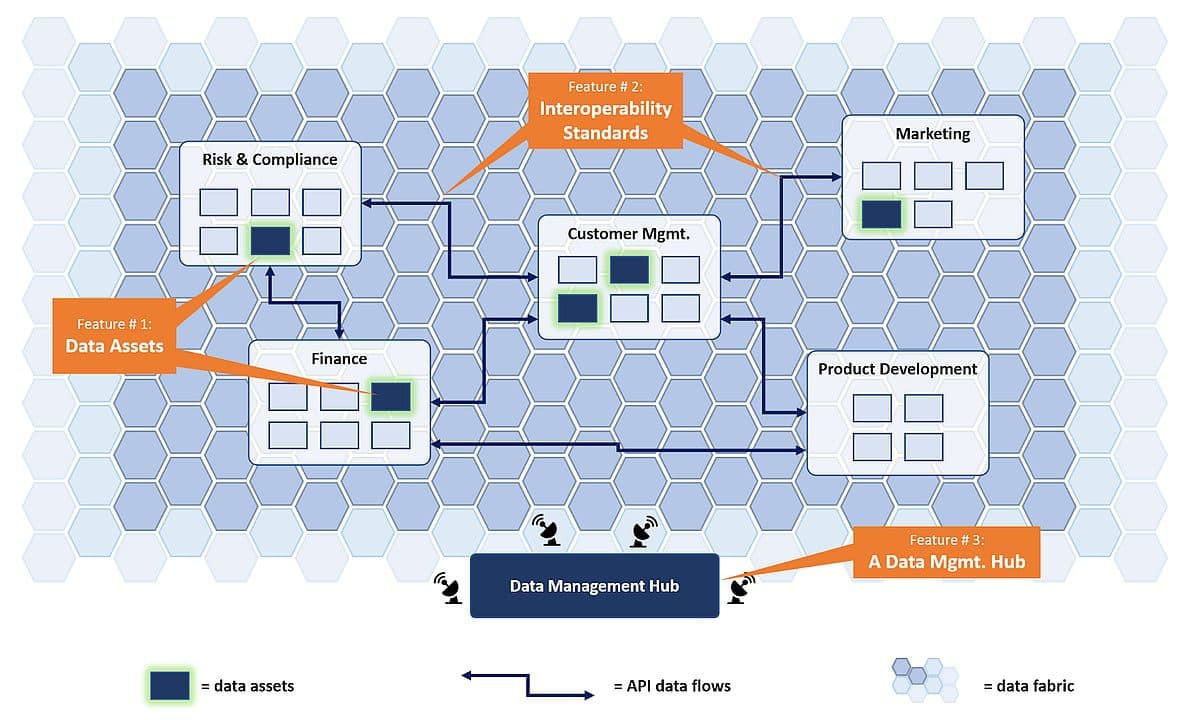
Data Assets
The first design feature is to embed specific Data Assets into your future state architecture. Data Assets (or perhaps Data Products, Trusted Sources, Authoritative Data Sources, or Systems of Record, depending on the nomenclature of your organization) are collections of data and information that are produced within a given (set of) business process(es), and that have a multitude of possible downstream users.
Given that a large group of consumers uses Data Assets, it is a logical location to implement data quality and governance controls. In that governed asset, the content is labeled and data quality is tightly controlled. Instead of identifying and measuring the data throughout the enterprise — which often results in inconsistent “versions of the truth” — there is a trusted distribution point for a given dataset, which also simplifies the organization’s overall architecture complexity.
In your future cloud-native architecture, the recommendation is to identify these Data Assets explicitly and manage them as such. This includes the approach that no matter what exact structure or tech stack is used for the asset, a minimum set of metadata is captured in an agreed format, and quality is controlled based on explicitly captured business requirements.
To ensure business process discipline, it is important to identify business process owners and clarify their responsibilities — such as consuming the right data from the right place and embedding controls for the data they produce and transform — because this directly influences quality.
It will depend on the complexity of the organization and the extent of the transformation, but typically managing just a handful of data assets will delight more than 90% of critical downstream users (often in reporting, analytics, data science, marketing, customer management, finance, accounting, and/or compliance roles).
Interoperability Standards
Having your most critical data governed in Data Assets is not enough. Now it needs to be accessed. Enabling access and integration into use cases, even if we don’t know what they are yet, is enabled by enforcing a set of interoperability standards. Interoperability standards are rules and protocols that drive the interaction and data exchange between systems and applications.
Consider electricity as an analogy. You can hook up any appliance to an outlet in your house, from a refrigerator to a string of Christmas lights or a phone charger, and expect it to work. So it is with data. You want to make sure your data (the electricity) is offered in agreed qualities and quantities, at a transparent price, through standard outlets available to anyone who has access to the various rooms in the house. Your enterprise must agree on the types of outlets and channels through which data will be delivered.
No one set of interoperability standards is the right answer for every organization, but several dimensions are critical:
-
Adherence to a data model to ensure consistent use and interpretation of data, at least for a minimum set of critical data.
-
Standard messaging and payload formatting.
-
Minimum business and technical metadata that is identified, maintained, and provided in standardized formats alongside systems and applications.
-
An identified set of compatible technologies.
A huge opportunity exists for organizations to ensure that data management is incorporated by design in future infrastructure by adopting an API-first mindset:
-
Specific API patterns can be defined to accommodate future data and information flow needs. Example patterns are asynchronous, synchronous, orchestration and data processing, and event-driven patterns.
-
Across patterns, align on metadata scripts or files made available alongside the API. These scripts should be standardized and contain a minimum set of business and technical metadata, such as the source, the destination, the frequency of the feed, included (critical) data elements, and a selection of indicators (e.g., classification, PII indicator). A best practice is that these metadata files are updated (if possible, automatically) each time the API is updated and maintained in an API catalog.
-
Ensure that the API metadata files are pushed or pulled into metadata management tooling in place so that lineage diagrams can be created.
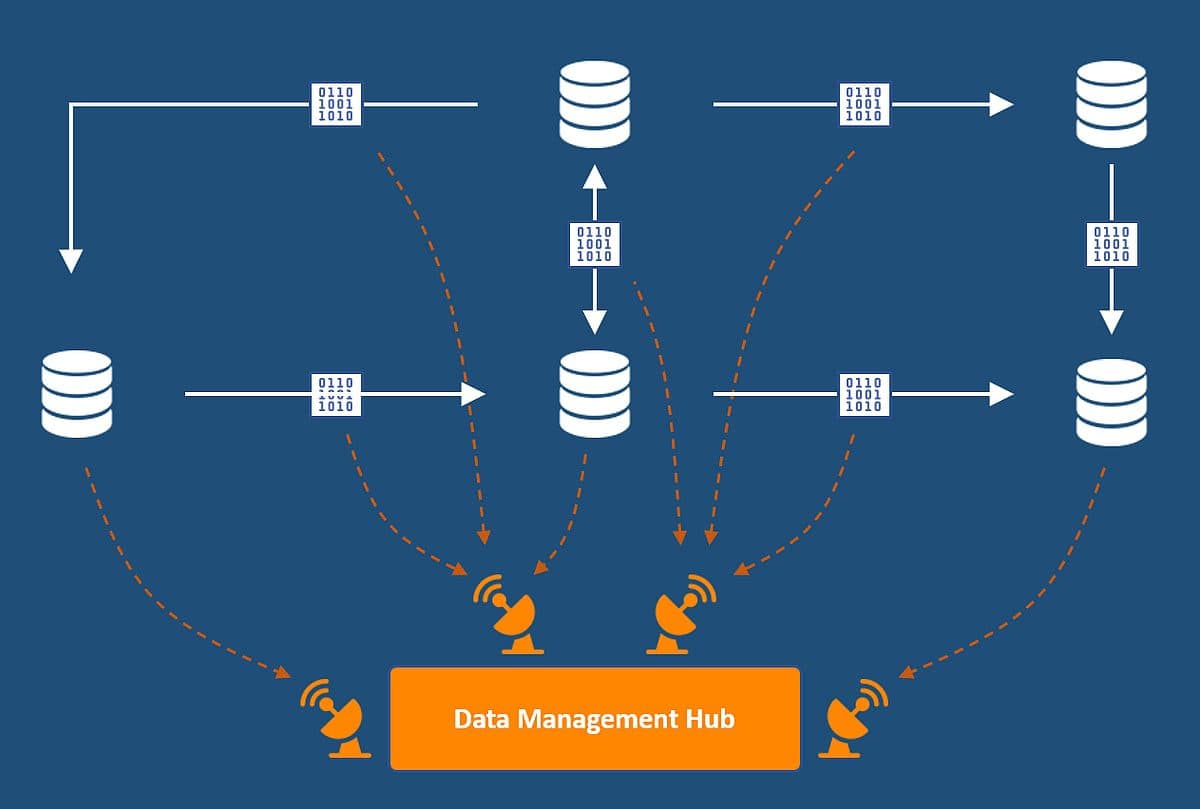
Data Management Hub
At this point, you have Data Assets for the most critical data of your enterprise, which you ensured is accessible because of a common set of Interoperability Standards. What is left is to ensure that data governance is automatically applied to the systems and applications of your cloud landscape.
Instead of having each transformation program or business/functional area reinvent the wheel in terms of how to ensure that master data is properly used, metadata is managed, and data quality is monitored, they should be able to self-service these capabilities from a Data Management Hub.
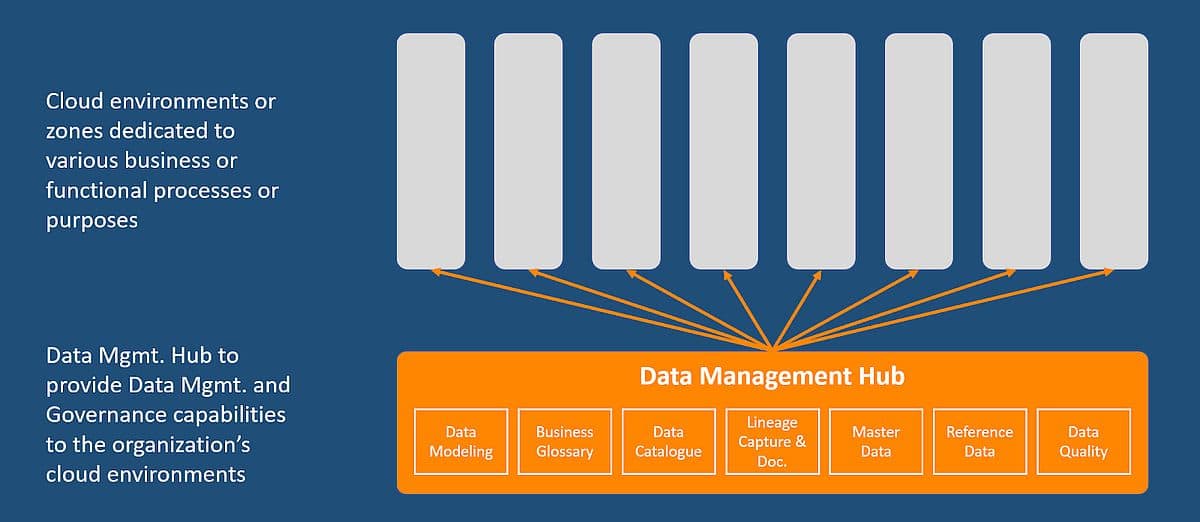
Several books could be filled with applications of intelligent data management from such a hub, but two are of particularly critical importance:
-
Discoverability — The combination of consistent minimum metadata requirements across systems and flows and the Data Management Hub that can engage any of your other environments drives data management by design. Any time a system or API is created, by definition, it will be discoverable and should be picked up by your metadata management scanner (and, if desirable, fed into a data catalog). No more after-the-fact hunting for data lineage!
-
Quality Controls — Controls that monitor and ensure data quality and integrity can be embedded in two principal ways. First, specific controls and restrictions can be applied for data creation, capture, transport, and usage. Examples include restrictions on the accepted or valid values and reconciliation checks in data flows. Second, quality controls can be implemented on data at rest in strategic locations, such as in Data Assets, to measure completeness, accuracy, and timeliness.
During large transformational programs, a wealth of knowledge is present in the minds of the program leads, architects, engineers, and analysts, who build the data systems and flows together. This institutional knowledge will erode over time as employees and contractors move on and spreadsheets grow stale. With the architectural tweaks outlined above and the organizational discipline to stick by them, your organization can manage its data offensively by design. This will enable consumers to find, access, and use Data Assets, accelerate the implementation of fit-for-purpose data governance controls, and avoid those large data remediation programs that no one wants to fund.
References
-
“BIAN Standards,” Banking Industry Architecture Standards, accessed October 2022.
-
“Cloud-Scale Analytics Data Management Landing Zone Overview — Cloud Adoption Framework,” Microsoft, accessed October 2022.
-
DAMA-DMBOK: Data Management Body of Knowledge.
-
Mutatina J, Yurtseven C, Blaauw, E, “From data mess to a data mesh,” Deloitte Insights, accessed October 2022.
-
Rick W, Sanjeev T, and Ashish V, “ To Democratize Data Access, Look Beyond Tech,” Wall Street Journal, accessed October 2022.
-
Strengholt, P, “Data Domains and Data Products,” Towards Data Science, accessed October 2022.
-
Strengholt, P, “Data Mesh: Topologies and domain granularity,” Towards Data Science, accessed October 2022.
-
Strengholt, P, “ABN AMRO’s data and integration mesh,” LinkedIn, accessed October 2022.
-
Thusoo, A, Sharma J, Creating a Data-Driven Enterprise with DataOps.
-
“What’s new in banking API programs,” McKinsey Digital, accessed October 2022.
About the Author
Willem Koenders is a Global Leader in Data Strategy at ZS Associates, with 10 years of experience advising leading organizations on leveraging data to build and sustain a competitive advantage. He has served clients across Europe, Asia, the United States, and Latin America. He previously served as Deloitte’s Data Strategy and Data Management Practice Lead for Spanish Latin America. He is passionate about data-driven transformations and a firm believer in “data governance by design.


