Nominate Now | Top 30 Healthcare Innovators 2026 List Honoring the Executives Driving Measurable Transformation and Responsible Innovation Across the Healthcare Ecosystem.
CDO Magazine Unveils the 40 Most Influential Data Leaders in Finance — North America 2026 Few industries are advancing data and AI as rapidly as financial services. From real-time payments and fraud detection to risk modeling, regulatory compliance, and AI-driven customer experiences, fina...
Webinar | Qlik How AI Is Forcing a Redesign of the Data Organization Date: March 26 Industry experts explore the emergence of new human–AI roles—from AI supervisors and agent coordinators to hybrid data leaders who combine domain expertise with AI fluency
Opinion & Analysis
Data Governance for Startups
Written by: Willem Koenders | Global Data Strategy Leader, ZS Associates
Updated 1:16 PM UTC, December 22, 2023

Data governance is typically not a startup’s primary concern, yet it is critical to power sustainable growth and protect against fatal operational and security risks. This article will sketch typical data environments in startups, outline the importance of data governance, and review standard data governance frameworks for tactical recommendations.
Startup data environments
Startups are often (on the verge of) experiencing rapid growth and an explosion in the amount of data they collect, generate, and process. They have agile processes as they are constantly iterating and experimenting with their products, services, and business models, and they often rely on AI-driven technologies to drive growth and innovation. This requires an adaptable data environment with the ability to rapidly incorporate new data sources and insights.
At the same time, resources are severely constrained in terms of budget, personnel, and time. This can make it difficult to invest in data infrastructure and governance. Data quality issues can be dealt with manually and ad hoc, directly in spreadsheets or programming code, as the number of customers and transactions are limited. Data ownership and stewardship are not formally addressed as the team is small, and team member responsibilities evolve quickly with the evolution and growth of the organization.
Relevance of Data Governance for startups
The first reason to drive the relevance of data governance for startups is to mitigate risks. As the volume and complexity of data increase, so does the risk of data breaches, cyberattacks, and compliance violations. This is a very real risk because startups are targeted by cybercriminals that see them as an easy target due to their limited resources and less robust security measures. For example, Code Spaces, a code-hosting and software collaboration platform, went from a promising business to ruin within 12 hours due to a cyberattack that got access to its cloud control panel. Implementing data governance practices helps companies mitigate these risks by establishing controls to protect sensitive data and ensure regulatory compliance.
The second reason is to ensure scalability. Storage space and processing power should be able to grow as needed with increasing customer interaction through digital channels. Friendster, MySpace, and Formspring are examples of startups that struggled to scale their data infrastructure to meet user demand1. Although other factors also played a role in their eventual demise, the inability to scale contributed to slow and unreliable platforms that frustrated users, and therefore to a decline in popularity. Conversely, Snapflix – a startup platform for managing and maintaining buildings that combines photos, tags, and messaging – turned interoperability (APIs that can interact with any smartphone) and scalability (instantly deployable for a one-person operation up to tens of thousands of users) into a driver of operational excellence and competitive advantage.
As the organization grows and expands, data becomes a shared asset that is used by multiple teams. Without governance, data is incorrectly shared (or not at all) and collaboration is reduced, taking away the sustainable foundation that is needed for data-driven analysis, experimentation, and prototyping. Data quality can no longer be addressed ad hoc, and unreliable data will cause errors, lower efficiency, and depress decision making.
The third reason is to directly impact the startup’s valuation. Investors are interested in startups with significant growth potential, where data on revenue growth, market sizing, customer acquisition, and user engagement can indicate a potential to grow. Startups also need evidence that they meet a real market need, and that is where customer feedback, usage pattern, and market trend data can come in useful. To demonstrate a competitive advantage, data on unique value propositions, intellectual property, and customer retention rates can provide the required evidence.
Investors will also base their valuation on the previously mentioned risk and scalability factors. They have seen many startups fail and shut down because of them, and they know that even a temporary setback can give competitors a chance to get ahead.
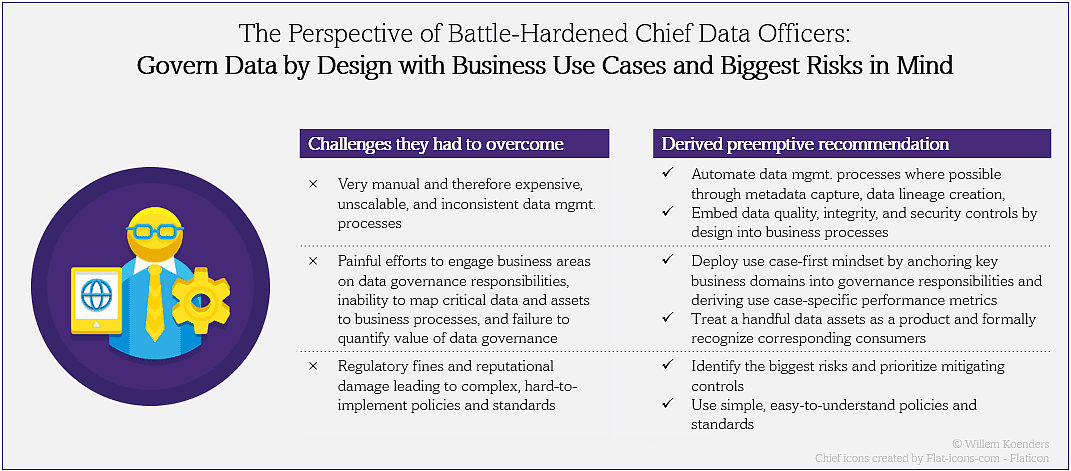
Applying standard data management frameworks
In the last few years, CDOs have faced a set of common challenges. Data governance emerged as a priority because of increased regulatory scrutiny, data quality and integrity issues, and an inability to use data to drive rapid innovation. A lot of time and effort was spent engaging domain owners to map critical data to business processes and use cases, and to get data owners to take on their responsibilities. Data governance controls tended to be manual and far removed from the source, and therefore repetitive and time-consuming. In some cases, progress was insufficient to ward off regulatory scrutiny and fines. Many companies overzealously committed themselves to writing long, complex policies and standards without adequately considering what could be reasonably implemented in the short to medium term.
A rich set of best practices emerged. Governance processes were automated, and controls were embedded directly into data flows, closer to (or at) the source. Documented risks and the corresponding policies and standards were simplified. Data ownership became a cornerstone of data governance, and at the moment of writing, “data as a product” seems to be the most fashionable term in all of data lingo. Industry-agnostic or -specific enterprise data models were adopted to standardize inconsistent logical models and facilitate data exchanges with external parties.
Organizationally, the split between IT, business, and data has always been problematic in the sense that data is owned by the business and housed within systems2. With ever bigger data teams and recurring territorial conflicts and finger-pointing (e.g., who is responsible for data quality?), savvy organizations reinterpreted data governance roles, shifting responsibilities back to business and IT teams (or “existing roles”).
The most-cited recommendation of them all: start small (e.g., with one domain), finetune your approach, and then scale across the rest of the organization. It could not be more readily applicable for startups with relatively small data landscapes, and which are yet to scale.
9 recommendations
Combining startup ambitions with CDOs’ lessons learned leads to a set of nine recommendations across three foundational layers:
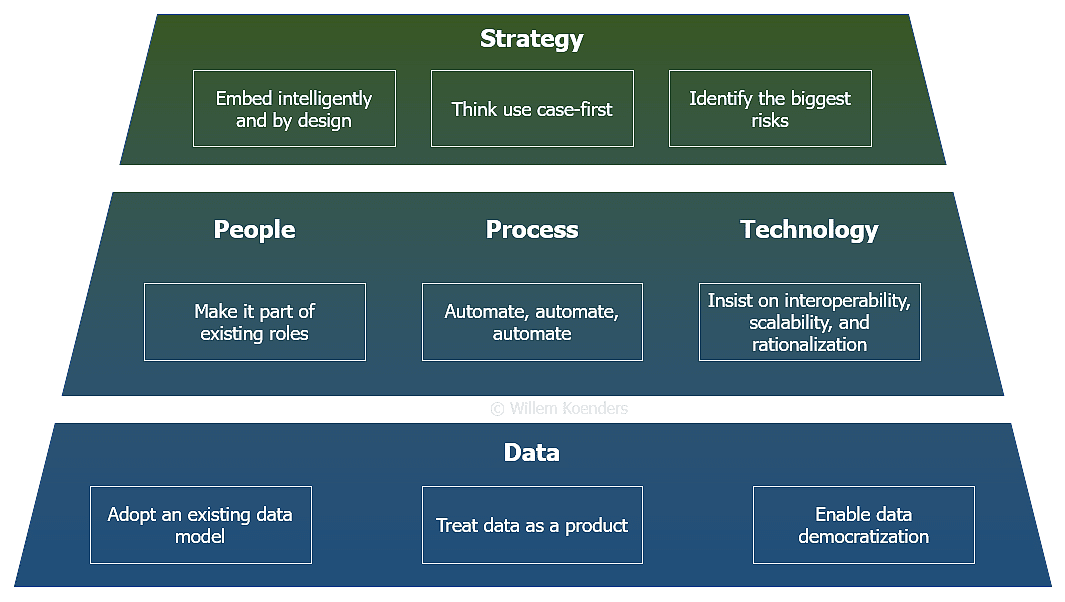
In terms of strategy, embed data governance by design to avoid painful remediation efforts later on, and target specific use cases that directly relate to the critical data that supports your startup’s valuation. Identify the associated biggest risks instead of trying to control for all of them.
Across people, process, and technology, empower existing business and tech teams, as creating dedicated data roles would reinforce the message that the data isn’t their problem. Adopt an automation-first (or automation-only) mindset, and whatever tech stack you choose, make sure it’s rationalized. Ensure it abides by a simple but strict set of interoperability and scalability principles.
In terms of data, govern data by treating it as a product that has customers, that can be innovated over time, and that can enable the democratization of data to the scientists and engineers that drive the startup’s products and services. Consider adopting an existing data model to accelerate the modeling process and to drive consistency both internally and with external partners.

Conclusion
Startups do not need to prioritize investing in expensive data management tooling, mobilizing big data quality teams, or mandating rigorous data literacy programs. Instead, prioritize getting the fundamentals right with the people and tools you already have. Tweak your existing data architecture and set of technologies, and embed data governance, security, and democratization straight into your business processes.
Past CDOs had to fight the perception of data as a bottleneck. Startups can stand on their shoulders, applying data governance surgically instead of radically, and create a data environment that supports growth and innovation while mitigating risk and improving efficiency.
About the Author
Willem Koenders is a Global Leader in Data Strategy at ZS Associate. He has 10 years of experience advising leading organizations on leveraging data to build and sustain a competitive advantage. Koenders has served clients across Europe, Asia, the United States, and Latin America. He previously served as Deloitte’s Data Strategy and Data Management Practice Lead for Spanish Latin America.Passionate about data-driven transformation, Koenders firmly believes in "data governance by design.”


