


Opinion & Analysis
What Are the Key Elements of Agile DataOps?
Written by: Diane Schmidt, Ph.D.
Updated 11:38 PM UTC, Thu April 18, 2024

Data Governance provides the guardrails by which an organization manages its data. Organizations vary in their missions and business objectives as well as drivers, outcomes, and expectations. However, there is a set of common tenets that apply regardless of entity type.
Agile and DevOps (ADO) uses a framework approach coupled with a quantitative set of controls and catalog to facilitate better-managed data and analytics, resulting in faster and better decision-making.
The Data Governance Program
A secure data platform with well-defined processes for access and use by data consumers enables data aggregation and integration. The final element of data aggregation is the adhesive that holds the service together, and the teeth that enable the enforcement of Data Governance Practices. This Federated Data Governance framework embodies the whole of ADO.
The Mission Statement
To enable effective data governance, an organization should consider, develop, and adopt a framework that begins with a simple mission statement to guide management and staff.
The 10 Principles of Data Governance
No two Data Governance programs are exactly alike because every organization functions differently, but the following 10 principles apply universally:
-
Develop a Mission Statement before you begin and govern with the consent of the governed.
-
Establish and continuously revise the data strategy, high-level objectives, and the key results governance is expected to achieve.
-
Be agile and uniform at intake and continuously capture and improve requirements.
-
Address today’s immediate problems first, iterate quickly to build good habits and obtain value.
-
Collaborate and give stakeholders ways to add knowledge and improve data assets.
-
Keep people, data, documents, and analysis connected and accessible from the beginning.
-
Make documentation easy and iterative (or it won’t happen.)
-
Promote good statistical and scientific methods.
-
Analytics is valuable while it’s happening, not just when it’s “done.”
-
The user experience must be twice as good as the products and practices it competes with to earn adoption.
The Data Governance Principles should be simple, clear, and concise, and designed to be understood by the casual business user who has no experience in data management.
The Data Strategy
Once the initial, formative objectives are established, the governing team should begin to develop a data strategy. Strategy is never “done” because the business climate, legal and regulatory environment, and financial markets constantly change, but it can be iterated over time and is often developed and redeveloped annually by the management as consensus builds on what works and what hasn’t worked.
A data strategy should begin with a vision of the fully realized strategy and a statement of measurable, expected outcomes, and it should step through the high-level components needed to realize the vision. It may include several key data control components, including:
The Data Control Environment
It is important to describe the core elements of the data platform in terms that the senior management can understand. Many platforms are moving to “cloud native” environments, hosted by highly capable vendors or internally on virtualized networks, but some organizations find the “hybrid, multi-cloud” approach to be pragmatic and cost-effective.
Sensitive information in any cloud should be monitored so management and security can understand where it is required and used so it can be monitored to prevent leaks or misuse. The range of potential use cases is massive and includes core data processing, integrations for more processing and analytics, reporting, and more. The data strategy needs to describe the holistic environment that will produce data products.
The strategy should identify the data collections that will need to be marked or tagged with one-to-many classifications so users can understand what it is, and whether it will be published as curated, endorsed, or certified data products.
It should discuss the framework for access controls to data that is ready for use, by the subject area, and the places where everyone will expect the data to be when ready for use. It should also suggest that pockets of data in silos, or stovepipes, will be scheduled for integration to eliminate redundancies.
The core, high-level data controls or standards can be described so the management will understand the care that is needed to prepare data products, such as access, movement, and master data standards. Other key concepts include Cataloging and Classifications, Protection and Privacy, and the end-to-end Data Lifecycle.
The Data Mesh approach allows and enables each domain within an organization to develop and maintain its own metadata model, ensuring “ownership” over how data is structured and used, but still applies federated Data Governance to ensure compliance between domains. Mesh also requires some sort of management framework to enable data sharing and disable data ownership.
The emerging best practice finds that the “ownership” paradigm, after decades of experience, proves that owners don’t share nicely and often drive counterproductive outcomes like the development of duplicate and sometimes erroneous data products, whereas, stewardship promotes the recognition that the organization’s best interests are served when sponsors, stewards and users are encouraged to share data and promote responsible reuse.
The Data Product Marketplace
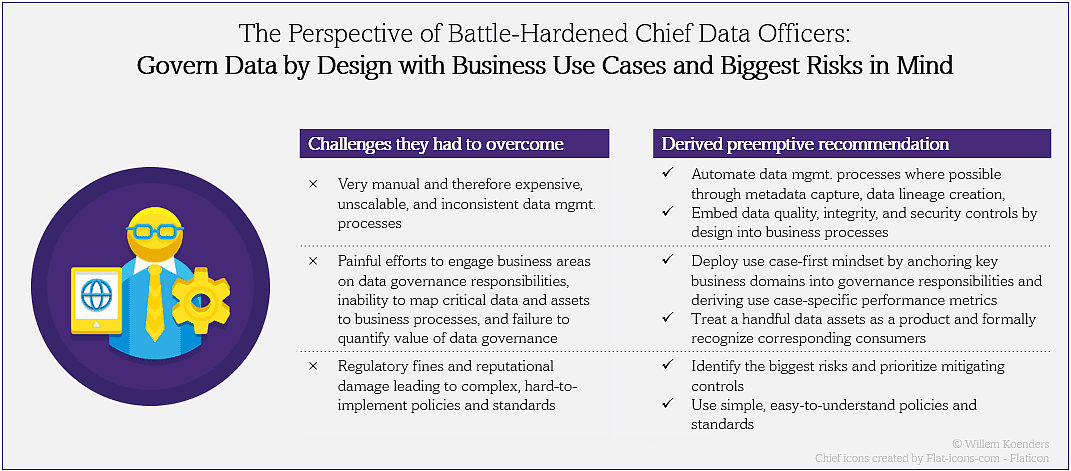
The catalog makes it easy to establish a documented method of federated Data Governance that balances centralization of global policies and decentralization by domain. And it acts as a data marketplace of sorts by making data products more discoverable and usable.
Critical to the Data Mesh paradigm is enabling the people who know the data best to maintain ownership while allowing self-service access by the people who need it. Data Governance is only effective when the data stewards, owners, and executives are empowered: to oversee the complete data lifecycle, develop metrics and measures, monitor adherence to standards, and drive accountability to ensure groups across the organization are adhering to Data Governance standards.
The Data Catalog
The Data Catalog (or Catalogs) plays a critical role in organizing structured and unstructured data and related artifacts, enabling smart enterprises to maximize data accessibility and interoperability. Essentially, a data catalog is an organized inventory of data assets used in business operations.

There are many modern tool options in the data catalog segment, but new leaders are emerging that harness the advanced capabilities needed for the next generation in cataloging. The future catalog is not just a list of assets, but the combination of, at the minimum, features that enable companies to operate seamlessly and scale up and out, effectively and efficiently.
-
An enumerated list of data sources and usually, their business context (i.e., a repository for HR or Finance business process data)
-
Explicit, current details, or metadata, about data assets
-
The semantic context and understanding of what those assets mean and how they are related to other assets, concepts, and data.
-
Tools to automate and enable work on large amounts of data (AI/ML, scripting, etc.).
-
A transport or integration layer that enables the automation of advanced analytics required for next-generation data workloads, such as a knowledge graph or a large language transformer model.
A carefully implemented data catalog with these next-generation capabilities enables organizations to establish a single point of reference, and vectors to select data assets while maintaining Positive Data Control with complete lineage and provenance.
The data catalog, while generally not a repository or warehouse and system of record for the Data itself, ingests metadata that supports corporate automation requirements, operational activities and decision-making processes to meet business operations, data processing, regulatory compliance and reporting, and advanced analytics to the myriad of stakeholders.
This metadata can be used by management, staff, auditing officials, and data scientists and researchers to enable decision-support by way of useful, reliable, high-quality evidence that is timely, relevant, and detailed enough to inform policy and procedures.
The data catalog further enables policymakers with self-service data access, provided safe in the knowledge that authenticated users are accessing trusted data that is accessible under permitted circumstances.
There are many types of metadata, but most practitioners are focused on delivering data organized by business, technical, operational, lineage, transformations and calculations, and provenance, or rights management. Regardless of the category, metadata enriches the value of the data to consumers.
Metadata serves several purposes, each of which contributes to business value proposition through the data platform:
-
Transparency is vital to realizing the promise of evidence-based policymaking, where “evidence-based” means including information as to what data mean and why they should be trusted. Transparency, in turn, requires that enough of this information is provided. Loosely speaking then, transparency is achieved when sufficient documentation is provided.
-
Metadata Automation is the ability to facilitate collection, visibility, and control of metadata. Data professionals across the spectrum spend a great deal of time and energy manually exploring, discovering, and understanding metadata. Automation, on the other hand, turns several weeks of manual labor into minutes and allows the business to move more quickly and efficiently.
-
Optimized Metadata Search makes it possible for analysts and technologists to find the data, whatever that data may be, within and across the broad data ecosystem, often across business units, agencies, or partnering organizations.
This provides value because it reduces duplication of effort and resources by agencies, supports change management opportunities, makes it easier to track who is responsible for the quality and timeliness of that data, identifies potentially marketable content, and identifies gaps in the data strategy that can be filled with investment in quality data sources.
-
Rich Analytics resulting from significant data preparation effort. Most data scientists spend more than 90% of their effort finding, cleansing, and refactoring data from one-to-many sources to begin analysis processes. The process of managing metadata also directly impacts the quality and interoperability of the data that the metadata describes.
In other words, the information that is generated by your operations, data scientists and business analysts is likely to be more accurate, timely, and those same people can spend more time mining that data for meaningful insights rather than simply spending their time compensating for bad data. And that means better information for future planning and decision-making.
-
Effective Data Governance and Metadata Management have a symbiotic relationship. Most Data Governance is focused on interpreting provenance (where data comes from), defining authoritative sources (what constitutes a primary or golden record), establishing stewardship (who is responsible for ensuring the operational integrity), validating definitions (how exactly the information is defined, often including citational context), temporality (when was the data first known and how often does it change), and business purpose (why was the data captured in the first place). Governance is largely involved with telling the “story” of data and its relevance to the organization.
-
Understanding and managing interactions with the external data environment is critical and often overlooked. Metadata management requires understanding and integrating data from the external environment. This includes data from constituents, vendors, counterparts, agencies, government, and regulatory organizations. Using emerging metadata standards and protocols such as ISO 8000, NIST, FISD and SIIA, prov-o, schema.org, and others, there’s a growing consensus about how to use and manage common structures – organizations, individuals, contracts and transactions, vehicles, scientific, biological, and medical information, and other subject areas that increasingly ensures at least an 80% solution for data interchange with the outside world.
However, making it easier to find data, that data must be trusted and endorsed by reliable stewards with controls established through data governance boards, working groups, and data governance operations.
Business Data Stewards
Data stewards are business users who know specific data well and are willing and able to play an active data management role for the good of the enterprise by providing continuous oversight of quality, integrability, and accessibility using the Data Catalog and through the Data Governance program.
Stewards must ensure data is trustworthy and that it is fit for the purpose it is intended to fulfill. They are responsible for defining or validating business rules, applying policies and standards, and managing data from its creation or capture through final disposition. Typically, data stewards are nominated by management based on knowledge of subject area data and process or due to line-of-business responsibilities.
Essentially, Stewards are the conduit for communicating issues associated with the data life cycle — the creation, modification, sharing, reuse, retention, and backup of data. If any issues emerge regarding the conformance of data to the defined policies over the lifetime of the data, it is the steward’s responsibility to resolve them.

Data Governance is everything. It’s the rules by which we manage data, enforce standards through our people model and the selected tools and technology. ADO helps leaders establish policies, standards, and procedures for data access, usage, controls, and other fundamental rules, driving transparency and accountability across the complete data lifecycle.
It emphasizes the key roles data product managers and stewards play in maintaining high-quality, accessible data within and across business and operational domains.
The data catalog, with rich content and well-defined processes, is an essential component for sharing, automation, and transparency, but the technology cannot guarantee optimal outcomes. Managed and measured ADO procedures for scanning, collecting, and distributing metadata are necessary to effectively operate enterprise data services that deliver data products.
The ADO team must develop metrics and measures, operationalize standards, monitor adherence, and ensure compliance throughout the organization. To this end, the semantic layer enabled by the catalog is essential to operationalizing the data and the relationships among data.
Authored with credit to Justin S. Magruder, Ph.D., Chief Data Officer, Science Applications International Corporation, Daniel Pullen, Ph.D., Chief Data Scientist, Science Applications International Corporation, Patrick McGarry, General Manager, US Federal, data.world, and Steve Sieloff, VP of Product Development & Thought Leadership, Vérité Data.
About the Author
Diane Schmidt, Ph.D., is former Chief Data Officer of the Government Accountability Office, the London Stock Exchange Group, and Freddie Mac. Schmidt has more than 25 years of experience in data management with a proven record of success in developing governance, operations, technology, analytics, and transformation programs.
She earned a doctorate in computer and information sciences, focusing on Information quality, and a Master of Science in Information Management. Schmidt is an active member of numerous data management industry forums, including board memberships with the Enterprise Data Management Council and the Arkansas National Science Foundation.


